Traduzione dal linguaggio di alto livello al linguaggio macchina
Un programma scritto in un qualsiasi linguaggio di programmazione di alto livello non può essere
compreso
e, quindi, eseguito da una macchina.
Affinchè esso possa essere eseguito è necessaria una
traduzione
nel linguaggio macchina specifico dell'esecutore.
A seconda del momento in cui viene
affettuata
la
traduzione, del linguaggio risultante e della quantità di codice tradotto, possiamo distinguere
i
seguenti approcci:
- compilato
- interpretato
- misto
L'approccio compilato prevede che la traduzione sia effettuata da un programma chiamato compilatore, che
riceve in input il programma scritto nel linguaggio di programmazione di alto livello e produce
in
output un programma scritto in linguaggio macchina, attraverso un lavoro in due fasi.
La
prima
fase
consiste nella traduzione vera e propria.
Il suo risultato è un codice
oggetto (non ancora
completamente eseguibile),
scritto in linguaggio macchina.
La seconda fase effettua un collegamento tra il codice oggetto
appena generato ed il codice oggetto di
eventuali librerie utilizzate, contenenti funzioni non native del
linguaggio utilizzato, ma
sviluppate
da altri programmatori, magari anche in altri linguaggi di programmazione, e messe a
disposizione in
termini di codice
oggetto, dopo opportuna operazione di traduzione.
La parte del compilatore che si occupa della fase di collegamento tra il codice oggetto
principale e
quello delle librerie utilizzate si chiama linker.
Le sequenza delle azioni di traduzione del programma iniziale (codice sorgente),
scritto in un
linguaggio di alto livello, e collegamento con le librerie utilizzate prende
il nome di compilazione.
Il risultato del lavoro svolto dal linker prende il nome di codice
eseguibile (file .exe di
windows).
Questo processo può essere sintetizzato graficamente dalla figura
seguente.
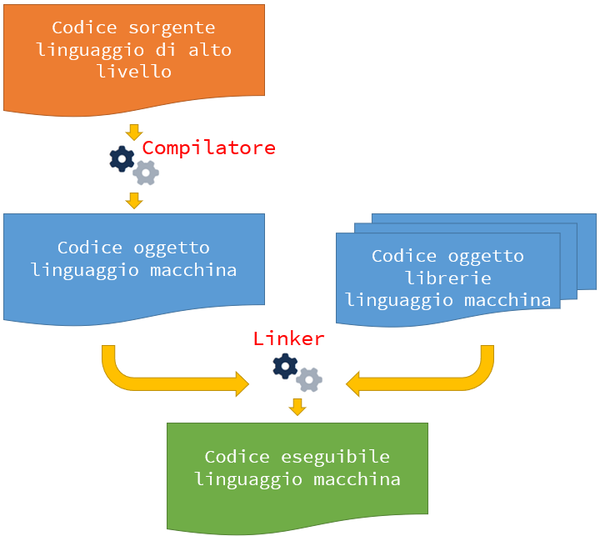
Vediamo ora nel dettaglio alcune caratteristiche della compilazione:
- è effettuata una sola
volta, al termine della
scrittura
del programma e deve essere eseguita nuovamente solo se il codice
sorgente necessita di
modifiche
per integrazioni di funzionalità o correzione di anomalie
- il codice eseguibile è generato traducendo l'intero
programma, e quindi, esso
potrà essere ottimizzato e
particolarmente efficiente per la
macchina su cui dovrà essere eseguito
- per eseguire il programma è necessario solo il codice
eseguibile, quindi, dopo la
compilazione, il codice sorgente può non essere più utilizzato, fino
ad eventuale necessità
di modifiche
- tutti gli errori
sintattici vengono rilevati
durante la
compilazione, perchè essa traduce tutto il codice sorgente, quindi
deve processarlo nella
sua
interezza
- il codice eseguibile generato è specifico per una
determinata tipologia di
macchina e,
quindi, non è portabile su macchine
con processore
differente; per
poter eseguire il programma su macchine differenti, occorre compilare
nuovamente lo stesso, con un
compilatore che produce codice macchina specifico per la famiglia di
processori di tale
macchina
- la fase di sviluppo del programma è più lenta, perchè ogni volta che si effettua una
modifica e si vuole testarne il funzionamento, occorre ricompilare tutto il programma nella
sua
interezza e tale operazione può essere dispendiosa, quando i programmi raggiungono
dimensioni e
complessità elevate
L'approccio interpretato prevede che la traduzione sia effettuata da un programma, chiamato
interprete,
che
deve essere in esecuzione sulla macchina su cui deve essere esguito il codice sorgente.
Tale traduzione, dal linguaggio di alto livello nel relativo linguaggio macchina, è effettuata,
una
istruzione alla volta, man mano che l'esecuzione del programma avanza.
L'istruzione corrente viene, quindi, tradotta in tempo reale ed eseguita sulla macchina sulla
quale
è in
esecuzione il programma interprete.
Questo vuol dire che la traduzione sarà effettuata ogni volta che il programma dovrà essere
eseguito
e
per le sole istruzioni coinvolte dalla particolare esecuzione.
Una sintesi grafica di quanto detto è rappresentata dalla figura seguente.
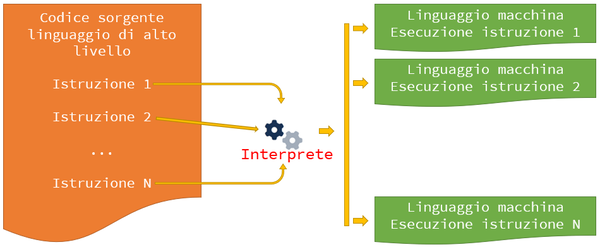
Esaminiamo ora nel dettaglio anche le caratteristiche dell'approccio interpretato:
- la traduzione è effettuata ogni volta che il
programma
deve essere
eseguito
- essendo la traduzione limitata alla sola istruzione corrente, tale approccio
non
considera il codice sorgente nella sua interezza e non è in grado di effettuare
ottimizzazioni
sul
codice macchina generato, risultando, per tale ragione, meno
efficiente
dell'approccio compilato
- il codice sorgente deve essere utilizzato ogni volta che il programma deve essere
eseguito,
in quanto l'interprete non salva nulla delle traduzioni effettuate, anche perchè ogni
esecuzione
potrebbe essere diversa dalle precedenti, in termini di flusso delle istruzioni eseguite e
tradotte
- il codice sorgente non è tradotto nella sua interezza e quindi potrebbe
accadere
che
una esecuzione vada in errore, a causa di errori sintattici
in
percorsi dell'algoritmo mai eseguiti,
anche dopo numerose esecuzioni terminate
con successo ed anche molto tempo dopo il completamento dello sviluppo del programma
- essendo il programma in linguaggio di alto livello indipendente dalla macchina
per
definizione, questo risulta portabile su macchine con
architettura
differente, purchè sia
disponibile, installato ed in esecuzione un interprete del linguaggio utilizzato
- la fase di sviluppo dei programmi, anche quando
questi
raggiungono dimensioni e complessità elevate, risulta più
efficiente,
in quanto non è necessario
attendere il completamento della traduzione di tutto il codice sorgente ogni volta che viene
implementata una modifica e deve esserne effettuato il test
Approccio misto (compilato e interpretato)
L'approccio misto vuole combinare i benefici di entrambe le
tecniche
viste
finora.
Esso si basa, infatti, su una prima fase di compilazione per
giungere
ad un codice intermedio portabile, eseguibile su macchine di tipo
differenze, attraverso un interprete specifico per ciascuna
macchina.
Diversi linguaggi di programmazione più usati al giorno d'oggi si basano su tale
approccio (Java, C#, VB.NET, ...)
Vediamo graficamente, nella figura che segue, come esso può essere rappresentato.
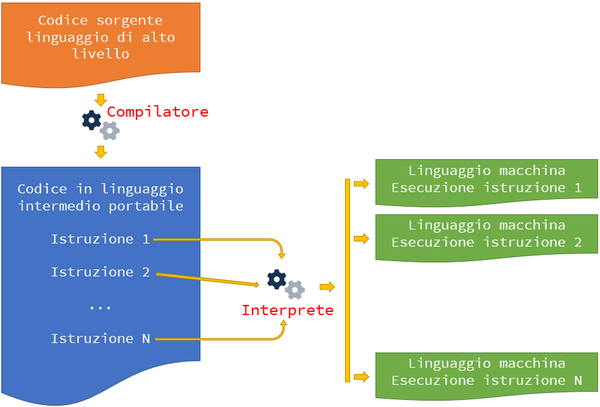
Concludiamo esaminando nel dettaglio le caratteristiche salienti di tale approccio:
- la prima fase di compilazione esegue una analisi di tutto il codice sorgente,
per
cui,
al termine della stessa, possiamo essere sicuri che il codice non
presenta
errori sintattici,
inoltre il codice intermedio generato è un codice ottimizzato
e
pertanto efficiente
- ogni esecuzione del programma necessita solo del codice
in
linguaggio intermedio,
generato dalla fase di compilazione, quindi, anche in questo approccio, dopo la
compilazione, il
codice sorgente può non essere più utilizzato, fino ad eventuale necessità di modifiche
- il codice intermedio, generato dalla fase di compilazione, risulta essere portabile ed
eseguibile su tutte le macchine che abbiano il suo interprete installato ed in esecuzione
- la fase di sviluppo, quando i programmi
raggiungono
dimensioni e
complessità elevate, è rallentata dalla necessità di
ricompilare
il
tutto
per poter effettuare il test, ma, rispetto all'approccio puramente compilato, risulta più
efficiente, in quanto la compilazione, avente come risultato il codice
intermedio,
risulta più
efficiente rispetto al stesso lavoro volto al risultato in codice macchina direttamente
eseguibile